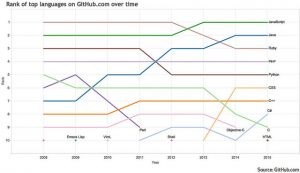
https://buzzorange.com/techorange/2016/09/30/legend-of-javascript/
接觸程式設計幾十年,看過多少程式語言的起起落落,這其中最讓我驚奇的,就是 JavaScript 語言了。許多人可能聽過 JavaScript 誕生的故事:1995 年 5 月,Netscape(網景)的 Brendan Eich 在公司要求下,花了 10 天創造出來的。只有 10 天!這麼倉促寫出來的程式語言,如今卻跑在全世界幾十億台運算裝置上。至今 JavaScript 開發者仍急速增長,並雄踞「
GitHub 熱門程式語言排行榜」榜首。
當年最耀眼的明星是 Java(準確的說是 Java applet,
今年剛被 Oracle 宣告終止 的一種技術)。我印象還很深刻:1995 年我在 Stanford 唸研究所的時候,有一天在同學宿舍的電腦看到瀏覽器裡跳來跳去的 Java Duke,當時大家那種興奮的心情。那是我們第一次在瀏覽器上看到會動的東西啊!至於 JavaScript(當時叫 LiveScript),大家跟本聽都沒聽過,更不用說去研究了。如果程式語言的世界也有勵志故事,JavaScript 的故事肯定能激勵其它程式語言:從小很窮幫人賣一些雜貨,沒人要做的髒活、苦活它都願意幹,辛苦奮鬥十幾年,終於有了今天的成就……
JavaScript 簡史
進展緩慢的 15 年
JavaScript 誕生於 1995 年。我寫 JavaScript,是從 1997 年的 Netscape/IE4 瀏覽器上開始的。在那個大家都用 C 寫 CGI 程式、用 Perl 語言就已經很潮的年代,JavaScript 不過是開發過程中的配角,那種電影結尾 roll 字幕才會出現名字的小角色。當時它多半負責檢查表單、alert 訊息、popup 視窗這類雜事。後來 DHTML 出現,JavaScript 可以修改網頁元件,戲份多了一些,但仍屬於配角。直到 2004 年 Gmail 推出,帶動 XHR/Ajax 相關技術發展,它才逐漸成為網站前端開發的主角。接下來幾年,JavaScript 與 Adobe Flex 分庭抗禮,成為當時 rich client 應用程式開發的兩大陣營(也許勉強再加上微軟 Silverlight)。
然而,JavaScript 語言的粗糙原始、加上瀏覽器(特別是 IE)相容性這兩大問題,15 年來並未獲得改善。用 JavaScript 開發應用程式,一直是件令人痛苦的事,是軟體開發者能不碰就不碰的語言。YUI、jQuery 等程式庫相繼出現,廣受歡迎,減輕了開發者的痛苦,但這並未改變 JavaScript 語言本身存在重大缺陷的事實。與 C++、C#、Java、Python 這些成熟語言比起來,JavaScript 顯得很寒酸,像個玩具語言、拼裝車。
突飛猛進的 5 年
2010 年 ES5(JavaScript 語言標準──ECMAScript 第 5 版)的推出,與 2011 年
Node.js/
npm 的出現,使事情開始發生變化。ES5 看似改變不大,其實解決了很多關鍵問題,是 JavaScript 邁向成熟語言的分水嶺。Node.js 則是幫助 JavaScript 切斷與瀏覽器的臍帶,使它成為一門獨立存在的語言,開啟了各種全新應用;於此同時,npm 解決了 JavaScript 多年來缺乏模組化套件資源庫的問題,各種 JavaScript 套件在 npm 平台如雨後春筍般冒出來,很多公司紛紛開始採用 JavaScript 開發大型前後端程式。(我在 2012 年寫的一篇英文 blog:“
JavaScript, a rising star”,記錄了我當時看到的一些現象,也預言 JavaScript 的興起,當然很多人也都看到了這一趨勢。)
2015 年 6 月,眾多開發者期待已久的 ES6(ECMAScript 第 6 版)終於定案。對 JavaScript 開發者而言,這可是一件大事!5 年前的 ES5,修正了 JavaScript 諸多缺陷,並促使 IE 瀏覽器往標準靠攏;ES6 則為 JavaScript 注入現代語言的重要特性,使 JavaScript 成為一個足以挑大樑的全方位程式語言。其實早在 ES6 正式定案之前,JavaScript 社群早已迫不及待開始用新標準開發程式了,各家瀏覽器也紛紛提早支援 ES6。比起當年 ES5 支援慢吞吞才到位的景象,不可同日而語。
不過在這期間,JavaScript 發生過一次重大危機。
io.js 分裂危機
過去 Node.js 的發展路線(roadmap)由
Joyent 公司主導,然而 Node.js 社群是由眾多志願者貢獻心力,才得以蓬勃發展。2014 年 12 月,幾位 Node.js 核心開發者不滿 Joyent 幾近獨裁的主導方式,決定另起爐灶,成立
io.js 計劃。(Node.js 的授權條款允許任何人重製改寫程式碼,只是不能使用 Node.js 的名字。)一開始 Joyent 態度強硬,無意改變他們的做法,但隨著越來越多使用者轉投 io.js 陣營的懷抱、加上 Node.js 因核心開發者的離開而陷入停滯,Joyent 終於讓步,接受 io.js 提出的條件,成立一個中立的 committee 主導未來 Node.js 發展。2015 年 6 月,雙方陣營一致通過,在新成立的 Node.js Foundation 之下共同合作。2015 年 9 月,由 Node.js v0.12 與 io.js v3.3 程式碼合併而成的 Node v4.0 正式發佈,Node.js 社群的分裂危機也隨之落幕。
以下我就分別介紹 ES6 的重大特色,以及我認為 JavaScript 專案開發應該注意的要點/常用工具。
一、ES6 重大特色
ES6 是 JavaScript 有史以來的最大改變,匯集了眾多頂尖工程師的智慧。與 Java、C#等由單一商業公司主導,或 Perl、Python、Ruby/RoR 等由 BDFL(Benevolent Dictator For Life──仁慈的獨裁者,一種技術開發社群給該技術創始人的稱號)主導的程式語言不同,現代 JavaScript 的發展,是由一些 JavaScript 社群的意見領袖、及許多 Internet 重量級公司指派的代表所組成的
ECMA TC39 Committee,在廣納各方意見之後做出的決定。這避免了過度仰賴單一公司的問題,也減少技術創始者個人偏好造成的影響。
Arrow Function
Arrow function 是 JavaScript 語法上的擴充,將原本 function (x) {...}.bind(this) 簡化為 x => ... 型式。別小看這個改變,它使得 JavaScript 能充份發揮 functional programming 特點,也使程式的可讀性、維護性及程式員生產力大為提高,是我最欣賞的 ES6 特色之一。
早期 JavaScript 雖然陽春,卻從一開始就有了 first-class function,也就是函式在語言中是一等公民(first-class citizen),可以被當作一般物件傳遞、回傳、指派。在那個物件導向程式設計獨領風騷的年代,這不能不說是 Brendan Eich 的遠見。(他的另一遠見,是讓 JavaScript 一開始就具備 prototype 物件導向的特性,這兩件事加在一起,使得 JavaScript 成為一個深具潛力的語言。)以下是
Brendan Eich 的一段話 :
I’m not proud, but I’m happy that I chose Scheme-ish first-class functions and Self-ish (albeit singular) prototypes as the main ingredients.
Object-Oriented Programming
ES6 終於賦與了 JavaScript 物件導向程式設計(Object-Oriented Programming)的正式語法,包括 class、extends、constructor 等等。在這之前,JavaScript 雖然能寫物件導向程式設計,但其語法蹩腳、違反直覺又不統一,每個程式員有他偏好的寫法,嚴重影響軟體開發維護的成本。
例如以下是新的 ES6 物件導向繼承寫法(假設類別 Shape 已經定義過了):
class Rectangle extends Shape {
constructor (id, x, y, width, height) {
super(id, x, y);
this.width = width;
this.height = height;
}
}
class Circle extends Shape {
constructor (id, x, y, radius) {
super(id, x, y);
this.radius = radius;
}
}
以下則是 ES5 的繼承寫法:
var Rectangle = function (id, x, y, width, height) {
Shape.call(this, id, x, y);
this.width = width;
this.height = height;
};
Rectangle.prototype = Object.create(Shape.prototype);
Rectangle.prototype.constructor = Rectangle;
var Circle = function (id, x, y, radius) {
Shape.call(this, id, x, y);
this.radius = radius;
};
Circle.prototype = Object.create(Shape.prototype);
Circle.prototype.constructor = Circle;
嚴格來說,JavaScript ES6 的物件導向程式設計,骨子裡還是 prototype-based,與 C++、Java 這些語言的物件導向運作原理不同。但對大部份開發人員來說,可能察覺不到這種差異,因為 ES6 的物件導向語法與傳統語言長得很像。ES6 物件導向語法的設計,採用了所謂「maximally minimal」的原則,也就是儘量縮小這次改變的範圍。至於日後 ES7 是否會為 JavaScript 注入更多物件導向特性,還有待觀察,因為不少人持反對意見。
Promises
JavaScript 是一種單一執行緒、以事件為基礎(event-based)的非同步程式語言。對於習慣用同步程式語言(synchronous programming language)寫程式的開發者,JavaScript 的單一執行緒似乎是件奇怪的事。但當你掌握訣竅之後,你會發現 event-based 的 JavaScript 處理各種非同步事件,其實比起傳統 synchronous multithread programming 更有效率。
不過這是有代價的。JavaScript 的 callback 對人類較不自然,比循序的程式難閱讀,callback 多層之後產生的「callback hell」,更是 JavaScript 開發人員的惡夢!維護這種程式既花力氣,又容易出錯。
Callback hell 大概長這樣:(實際上更難看,因為還有錯誤處理的程式碼,而且 callback function 可能定義在其它地方)
getData(function (a) {
getMoreData(a, function (b) {
getMoreData(b, function (c) {
getMoreData(c, function (d) {
getMoreData(d, function (e) {
...
});
});
});
});
});
生命會尋找出路。有人開始把 concurrent programming 裡的 promise 搬過來用,將層層 callback 轉為一連串簡單的循序呼叫,幫助 JavaScript 開發人員遠離 callback hell 惡夢。在 ES5 時期,就已經有很多第三方 Promise 程式庫了,ES6 則進一步把 Promise 納入標準,成為 JavaScript 的標準物件。
Generators
我第一次接觸 generator 這個觀念,是 2002 年左右在 Python 2.2 看到的,那時我已經用 Python 加 C++ extension 寫大型 Python 程式好幾年了(從 Python 1.5 開始)。對於習慣 synchronous programming 的我,第一次看到 generator 真的很陌生:函式執行到一半可以先返回,下一次被呼叫再接著往下執行。我到後來才慢慢搞清楚這件事。
ES6 的 generator 除了作為 iterator,另一個重要用途是把
yield 當作呼叫非同步函式的關鍵字。搭配像
co 這樣的程式庫,在 JavaScript 裡處理非同步呼叫(例如呼叫外部伺服器 API、存取資料庫、操作 cache layer 等等)變得異常簡單。Promise 已經大大簡化了非同步程式的開發,generator(加上 co)則進一步把它變成一行簡單的函式呼叫。在 ES7 的 async/await 到來之前,generator 是 ES6 送給 JavaScript 開發者的大禮,也是我最欣賞的另一個 ES6 特色。
其它 ES6 重要特性
以上 4 個是我認為最重大的改變。當然還有一些 ES6 特性也很重要,例如:
- const/let:有了
const 與 let,JavaScript 開發者應該把 var 收到抽屜裡了。var 有許多奇怪特性,let 則文明得多。此外,能用 const 就用 const,你會發現程式碼可讀性大大提高。(別小看這件事,一旦你知道一個變數是 const,它在你讀程式過程的 cognitive load 就會輕很多,能幫助你大腦騰出更多空間裝其它東西。)
- string interpolation:有了 string interpolation 語法,從此少掉一堆字串相加的算式,讓字串歸字串,程式歸程式。
- module import/export:模組的定義和引用,終於成為 JavaScript 標準的一部份,從此不再需要用
require 作為替代方案。
- 其它:for-of,property shorthand,array matching,object matching,
Object.assign……等等。
二、關於 JavaScript 專案開發
對 JavaScript 語言的掌握
和其它語言相比,JavaScript 語言有一些較特殊的地方,例如:
- var scope/hoisting
- closure
this- strict mode
- ==/===的差異
……等等。這裡面有許多細節(甚至地雷),JavaScript 開發者對這些應該要清楚掌握,以免不小心犯錯,造成程式 bug。
Node.js 與 npm
2009 年,Ryan Dahl 以 Google 的 V8 JavaScript 引擎為基礎,加上 event loop 及一套非同步 I/O 程式庫,創造出 Node.js。去掉對瀏覽器的依賴,Node.js 成為可以在 Linux 環境下獨立執行的 JavaScript 直譯器,解開封印,為 JavaScript 開啟了一個全新時代。(第一個 Windows 版本的 Node.js,則是 2011 年由 Joyent 與 Microsoft 共同完成。)Node.js 雖然基於 Google V8 JavaScript 引擎,卻有它自己的執行環境與程式庫(例如 EventEmitter、Stream、http.Server 等等),與瀏覽器端的 JavaScript 行為有諸多不同之處。
2011 年,Node.js 的套件管理員(package manager)npm 推出,為 Node.js 開發者提供極大方便,也使 JavaScript 套件的協作、共享變得非常容易。npm 是 JavaScript 專案開發不可或缺的工具,搭配簡單的 shell command,在不使用 Grunt、Gulp 等建置工具的情況下,npm 甚至足以處理許多專案的建置與部署需求。事實上,有不少人(包括我在內)認為用 npm 就可以了,例如這篇文章:
Why I Left Gulp and Grunt for npm Scripts
ES6 轉譯
由於使用者端的瀏覽器並不一定支援 ES6,將 ES6 程式碼轉為瀏覽器能執行的 ES5,就成了部署 JavaScript 程式碼的標準程序之一。過去這種轉譯工具(transpiler)有很多,例如 6to5、Google traceur 等等。自從 6to5 改名為
Babel 之後,Babel 似乎就成為大家的標準工具了。
除了將 ES6 程式碼轉換為 ES5,Babel 還能處理更多的事,例如轉換 React JSX 語法、移除 Flow 型別註記、甚至支援 ES7 async/await 等等。
程式碼檢查工具
JavaScript 是一種動態程式語言(dynamic programming language)。對於習慣靜態程式語言(static programming language,例如 C/C++、Java)的開發者而言,動態程式語言一開始很方便。不用事先宣告變數型別,太棒了;不用 compile 就能執行,多好!也不會有 compile error 了。不過很快你就會發現,這只不過是把 bug 留到 runtime 再爆開來而已,bug 並沒有自動消失。相反的,runtime 才出現的 bug,代價比 compile-time 要高很多,很可能從 5 分鐘變 5 小時、甚至 5 天。
修復 bug 的成本,由小到大依序是:compile-time,testing,production runtime。對於沒有 compile-time 的動態程式語言來說,如何避免在 runtime 才發現 bug,就成為一個重大課題。(當然靜態程式語言也是,但它們通常在 compile-time 就能找出許多 bug,也有更多程式碼檢查工具可供選擇。)
在 JavaScript 開發社群中,使用 linter(一種靜態檢查程式碼錯誤的工具)的做法非常普遍。早期被普遍使用的 JavaScript linter,是 Douglas Crockford 寫的
JSLint。後來
JSHint 出現,變得很受歡迎。
ESLint 則是 Nicholas Zakas 開發的另一種 JavaScript linter,也是我個人目前在用的。無論哪一種,專案團隊都應該採用 linter 檢查程式碼,並藉此統一 JavaScript 程式碼的 coding style。
型別宣告及檢查
缺少型別宣告(type declaration)及 compile-time 型別檢查,是動態程式語言的另一項弱點。在 JavaScript 開發社群中,解決這個問題的常見選擇有兩種:
TypeScript 或
Flow。TypeScript 是微軟開發的 JavaScript 擴充語言,有方便的 IDE 環境,並且對 Windows 開發環境有很好的支援;但若你的專案原本沒有採用 TypeScript,想要漸進導入,可能會面臨一些挑戰。Flow 是 Facebook 開發的 JavaScript 型別檢查工具,採用與 TypeScript 類似的型別註記語法;因為 Flow 可以自動分析既有程式碼的型別,有助於專案漸進導入型別註記,但對 Windows 開發環境的支援度則較弱。Flow 比較類似「非侵入性」的解決方案,如果開發環境允許,我個人推薦 Flow。
單元測試
動態程式語言比起靜態程式語言更需要單元測試(unit test)。JavaScript 的單元測試框架有很多種,早期被廣泛使用的是
Jasmine 與
Mocha。近年則有許多人提倡回歸到更簡單、更模組化的單元測試框架(例如
這篇文章),包括
Tape 與
AVA 等;其中由 Tape 演變而來、加入平行執行能力(因此能大幅縮短單元測試執行時間)的 AVA,特別引起 JavaScript 開發社群的注意,短短一年多,已在 GitHub 上獲得大量關注。
單元測試不是免費午餐。測試程式碼一樣要花人力撰寫維護,因此它的品質也很重要。根據我過去的工作經驗,測試程式碼的品質通常較差,這可能是因為很多人(尤其主管或 PM)只看到 test coverage 數字,這部份需要注意。
了解你用的每樣東西
由於 npm 及 GitHub 帶來的便利,世界上已經有超過 20 幾萬種 JavaScript 套件與各種工具。這雖然給 JavaScript 開發者更多選擇,卻也常導致 JavaScript 專案有過多的、不必要的外部依賴關係(external dependency)。開發團隊應該謹慎評估每一個要使用的套件與工具,確實了解它們的用途及必要性,而非盲目引入,以免造成日後專案維護的負擔。例如:你用了建置工具 Gulp,原始碼就有了 Gulp code,團隊成員要學習 Gulp;你用的每個 Gulp plugin,在日後開發環境版本更新時有可能壞掉,如果 plugin 作者不再維護更新、或更新速度較慢,你就得自己跳進去維護;等等。任何工具都有它的用途,能解決某些問題,但我們也要注意它的總體擁有成本(Total Cost of Ownership,TCO)。
結語
JavaScript 是普及率最高的程式語言之一,很多開發者對它都不陌生,這使得 JavaScript 進入門檻相對較低。另一方面,如果團隊採用 JavaScript 作為開發的主要語言(包括伺服器端),還可以統一前後端語言,在團隊專業經驗培養上具備更大優勢。
今天的 JavaScript 早已不是當年那個陽春的小玩意兒,而是有著豐富成熟語法、大量第三方程式庫支援,令人寫起來愉快的現代化語言。
許多知名公司 包括:LinkedIn、Netflix、New York Times、PayPal、Uber、Yahoo 等,早已使用 Node.js/JavaScript 開發產品多年。充份運用 JavaScript 語言的最新特性,輔以適當的工具與流程,JavaScript 將會是一個高效能、高生產力的開發利器。
限於篇幅,以上只是簡單介紹,希望這篇文章,能幫助大家對現代 JavaScript 語言有一個初步認識!

 Remi El-Ouzaane,Movidius副總裁兼總經理Remi El-Ouazzane
Remi El-Ouzaane,Movidius副總裁兼總經理Remi El-Ouazzane Movidius Myria 2 VPU方塊圖 (來源:Intel/Movidius)
Movidius Myria 2 VPU方塊圖 (來源:Intel/Movidius) (來源:Movidius)
(來源:Movidius)